Lesen, Hören, Gucken, Schreiben

(c) Zonix 2005
Was?
Inkohärentes Geschreibsel eines Late Adopters
Ralph
E-Mail oder kontaktiert range im IRCNet oder auf Freenode.
Bilder
Ralphs Bildergalerie
Feed Me!
Hier gibt es einen RSS-Feed. Oder folgt mir bei Twitter.
| Februar 2015 | ||||||
|---|---|---|---|---|---|---|
| So | Mo | Di | Mi | Do | Fr | Sa |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Einträge nach Datum:
- Januar 2012 (1)
- Oktober 2010 (1)
- Maerz 2010 (1)
- Oktober 2009 (1)
- September 2009 (1)
- Juli 2009 (3)
- Juni 2009 (3)
- Mai 2009 (1)
- April 2009 (1)
- Maerz 2009 (4)
- Januar 2009 (2)
- Dezember 2008 (3)
- November 2008 (1)
- Oktober 2008 (2)
- September 2008 (2)
- August 2008 (3)
- Juli 2008 (2)
- Juni 2008 (5)
- Mai 2008 (2)
- April 2008 (9)
- Maerz 2008 (2)
- Februar 2008 (2)
- Januar 2008 (4)
- Dezember 2007 (2)
- November 2007 (6)
- Oktober 2007 (5)
- September 2007 (13)
- August 2007 (8)
- Juli 2007 (4)
- Juni 2007 (5)
- Mai 2007 (7)
- April 2007 (8)
- Maerz 2007 (9)
- Februar 2007 (3)
- Januar 2007 (5)
- Dezember 2006 (1)
- November 2006 (4)
- Oktober 2006 (1)
- September 2006 (2)
- August 2006 (6)
- Juli 2006 (7)
- Juni 2006 (8)
- Mai 2006 (10)
- April 2006 (11)
- Maerz 2006 (19)
- Februar 2006 (14)
- Januar 2006 (13)
- Dezember 2005 (15)
- November 2005 (18)
Kategorien:
- administriva - 6
- bücher - 1
- centos - 25
- computer - 26
- design - 1
- freesoftware - 2
- hardware - 4
- internet - 11
- linux - 3
- mail - 2
- filme - 3
- fotos - 6
- kram - 42
- sprache - 6
- lifestyle - 13
- medien - 10
- musik - 29
- hören - 8
- konzerte - 8
- politik - 32
- tv - 6
- ueberraschung - 19
- unmut - 33
- verkehr - 9
Auch lesbar
Na, einfach shrek[]
Sieh die Welt mit meinen Augen
Das Schwätzbrett
Das Bildblog
D'ohne Pointe
Howto generate password for proftpd mod_sql_passwd
2012-01-10As I spent a few hours with figuring out on how to generate passwords which are usable with the mod_sql_passwd module in proftpd, I’d like to share how to do this. I am using the username as a salt, if you don’t want a salt, just drop it from the echo.
# md5 hex encoded # SQLPasswordEncoding hex # SQLAuthTypes MD5 # SQLPasswordUserSalt name Prepend # salt == username, password == password /bin/echo -n "usernamepassword" | openssl dgst -hex -md5 d51c9a7e9353746a6020f9602d452929 # md5 HEX encoded # SQLPasswordEncoding HEX # SQLAuthTypes MD5 # SQLPasswordUserSalt name Prepend # salt == username, password == password /bin/echo -n "usernamepassword" | openssl dgst -hex -md5 | tr [:lower:] [:upper:] D51C9A7E9353746A6020F9602D452929 # sha256 base64 encoded # SQLPasswordEncoding base64 # SQLAuthTypes SHA256 # SQLPasswordUserSalt name Prepend # salt == username, password == password /bin/echo -n "usernamepassword" | openssl dgst -binary -sha256 | openssl enc -base64 vtklQtp0DL5YesRbeQEgeheiVjaAss7aMEGVonM/FL4=The other variants are similar. Two important things: you need
echo
-n as that removes the newline from the echo command and if you use
base64, you need the binary digest - for md5 and all the sha variants. This
is somehow not needed for the hex and HEX encoded passwords.
I hope someone finds this (at all and) useful.
Geschrieben um 12:07
[/computer] [permanent link] [Startseite]
Ich hasse Rails
2009-03-25Oder anders gesagt: Ich hätte gerne die Drogen, die die Entwickler nehmen. Oder noch anders gesagt: Wer schenkt den Entwicklern mal ein Buch über Unix-Dateisystemrechte?
[root@kiste:/var/log/rails #] ls -l . drwx------ 2 apache apache 4096 25. Mär 16:21 . [root@kiste:/var/log/rails #] service httpd graceful [root@kiste:/var/log/rails #] tail -1 /var/log/httpd/error.log Rails Error: Unable to access log file. Please ensure that /var/log/rails/production. log exists and is chmod 0666. The log level has been raised to WARN and the output di rected to STDERR until the problem is fixed. [root@kiste:/var/log/rails #] touch production.log [root@kiste:/var/log/rails #] service httpd graceful [root@kiste:/var/log/rails #] tail -1 /var/log/httpd/error.log Rails Error: Unable to access log file. Please ensure that /var/log/rails/production. log exists and is chmod 0666. The log level has been raised to WARN and the output di rected to STDERR until the problem is fixed. [root@kiste:/var/log/rails #] chmod 0666 production.log [root@kiste:/var/log/rails #] service httpd graceful [root@kiste:/var/log/rails #] tail -1 /var/log/httpd/error.log Rails Error: Unable to access log file. Please ensure that /var/log/rails/production. log exists and is chmod 0666. The log level has been raised to WARN and the output di rected to STDERR until the problem is fixed. [root@kiste:/var/log/rails #] chmod 0770 . [root@kiste:/var/log/rails #] service httpd graceful [root@kiste:/var/log/rails #] tail -1 /var/log/httpd/error.log Rails Error: Unable to access log file. Please ensure that /var/log/rails/production. log exists and is chmod 0666. The log level has been raised to WARN and the output di rected to STDERR until the problem is fixed. [root@kiste:/var/log/rails #] chmod 777 . [root@kiste:/var/log/rails #] ls -ld . drwxrwxrwx 2 apache apache 4096 25. Mär 16:21 . [root@kiste:/var/log/rails #] service httpd graceful [root@kiste:/var/log/rails #] tail -1 /var/log/httpd/error.log [Wed Mar 25 16:22:35 2009] [notice] Apache/2.2.3 (CentOS) configured -- resuming normal operations [root@kiste:/var/log/rails #]
Ach ja, rails läuft natürlich als User apache. AAAARGH!
Geschrieben um 16:39
[/computer] [permanent link] [Startseite]
Kinder-Unix
2008-12-03Man merkt schon, dass ein großer Teil der Entwicklung am Linuxumfeld — also nicht unbedingt am Kernel selber — auf dem Desktop passiert, damit man Linux einfacher handhaben kann. Oberflächen wie Gnome und KDE sind mittlerweile soweit, dass ich sie persönlich als genauso “einfach” und “selbstserklärend” empfinde wie die Oberfläche von Mac OS und wahrscheinlich auch Windows — da bin ich auf dem Stand von XP und kann daher nicht viel dazu sagen.
Auf der anderen Seite gibt mir eine Linuxdistribution aber immer noch die Möglichkeit unter der Haube so anpassbar zu sein, dass ich mir das System nach meinem Belieben zusammenbiegen kann - und dabei natürlich auch die Möglichkeit, mir so feste und so oft in den Fuß zu schießen, wie ich möchte.
Von daher hat mich folgendes schon ein wenig verblüfft:
--no-preserve-root do not treat `/' specially\n\ --preserve-root do not remove `/' (default)\n\
Das ist aus rm.c und bedeutet, dass seit den Coreutils 6.10 — da
finde ich es zum ersten Mal — der Befehl rm sich per default weigert, ein
rm -rf / auszuführen, sondern das mit der Fehlermeldung rm:
cannot remove root directory '/' zu quittieren. Natürlich kann man das
mit der Option --no-preserve-root abschalten und auch ein
cd /; rm -rf .* funktioniert.
Es muss einen Grund geben, dass der Default umgestellt wurde, schließlich war das eine der effizientesten Methoden sich ein großes Loch in den Fuß zu schießen. Kindersicherung — sicherlich — aber es bleibt die Frage: Warum?
Geschrieben um 12:34
[/computer] [permanent link] [Startseite]
Captchas riechen nicht mehr komisch, sie sind tot
2008-08-30Captchas (Completely Automated Public Turing test to tell Computers and Humans Apart) sind diese kleinen schlecht lesbaren Bildchen auf denen nicht erkennbare Buchstaben und Zahlen abgelesen werden müssen und dann in ein Textfeld eingegeben werden sollen. Damit ist es angeblich möglich, Computer und Menschen auseinanderzuhalten, da nur Menschen in der Lage sein sollen, diese Bilderrätsel zu lösen. Habe ich in diesem Artikel ein System vorgestellt, welches Captchas vollautomatisch löst — und dabei Captchas erkennt, an denen ich regelmäßig scheitere — ist die “menschliche” Erkennungsrate wohl doch noch höher.
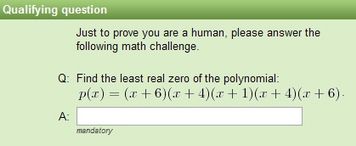 Diese Captchas sollen mittlerweile nicht mehr nur vor Spam schützen — hier vor allem in Webforen oder auf Wikis — sondern auch Banken oder Webmailer wie Googles gmail.com setzen auf diese Methode, um automatisiertes Anlegen von Accounts zu erschweren oder um dem Kunden einen angeblichen weiteren Schutz beim Onlinebanking zu geben. Kein Wunder, dass es immer mehr Menschen gibt, die Interesse daran haben, solche Captchas generell lösen zu können — natürlich nicht immer für lautere Zwecke.
Diese Captchas sollen mittlerweile nicht mehr nur vor Spam schützen — hier vor allem in Webforen oder auf Wikis — sondern auch Banken oder Webmailer wie Googles gmail.com setzen auf diese Methode, um automatisiertes Anlegen von Accounts zu erschweren oder um dem Kunden einen angeblichen weiteren Schutz beim Onlinebanking zu geben. Kein Wunder, dass es immer mehr Menschen gibt, die Interesse daran haben, solche Captchas generell lösen zu können — natürlich nicht immer für lautere Zwecke.
Auftritt Indien: Dort hat sich “Captcha Solving” zu einer mittelgroßen Industrie gemausert. Firmen, die versprechen, 800 Captchas pro Stunde zu lösen, Datentypisten, denen US-$ 2,- pro 1000 gelösten Captchas gezahlt — alles natürlich unter dem Anschein der Legalität: “Wir lösen Captchas für sehbehinderte Personen, ermöglichen Wissenschaftlern die GMAIL-Captchas für ihr Projekt zu lösen”, aber in Wirklichkeit wird das natürlich alles für das organisierte Verbrechen genutzt.
Dancho Danchev hat in seinem Blog bei ZDNet einen erschreckenden Artikel zu dem Thema geschrieben. Man kann mit Gewißheit sagen: Captchas sind tot. Zumindest dann, wenn damit etwas von Wert geschützt werden soll. Und das im großen Stil. Wieder ein Sieg für das Verbrechen, wieder ein Verlust für die, die das Web nutzen wollen für Diskussionsforen, Wikis, Bugtrackingsysteme usw. — also alle Systeme, die davon leben, dass Menschen “von außen” leicht Kommentare oder Texte hinterlassen können.
Geschrieben um 18:24
[/computer/internet] [permanent link] [Startseite]
Schöne Grüße …
2008-03-02von den 10. Chemnitzer Cateringtagen (mit Linuxvorträgen). Prost!

Geschrieben um 10:29
[/computer/linux] [permanent link] [Startseite]
Spam in Webforen
2007-07-25Sie sind die Furunkel am schmutzigen Arsch des Internet: Spammer, die jegliches Kommunikationsmedium im Internet mit ihrer Werbung zumüllen. Sei es Mail, Usenet, Wikis, Blogs oder Webforen - kein Medium ist vor ihnen sicher. Nehmen wir mal Webforen als Beispiel: Wer hat sich bisher nicht gefragt, wie Spammer hunderte von Foren mit ihrem Müll verpesten?
Die Blogger der Securityfirma Pandasoftware haben jetzt ein Tool entdeckt, was diese Einträge automatisiert vornimmt — oder habt ihr etwa gedacht, dass Spammer “zu Fuß” von Forum zu Forum hoppeln? Das ist eine sehr beeindruckende Software, die in zwei Teilen kommt: Hrefer durchgräbt Suchmaschinen nach Webforen und sammelt diese Links. XRumer nimmt diese Links dann entgegen und verbreitet Werbedreck in den Webforen.
Und zwar vollautomatisiert: Wird ein Webforum entdeckt, legt die Software einen User an, wartet auf den “Activiation Link”, der normalerweise per Mail zugeschickt wird, aktiviert den Account und posted dann die Werbung in das Forum.
Aber dagegen kann man sich ja mit einem Captcha schützen — diesen unleserlichen Zeichenketten, mit denen man beweisen kann, dass man ein Mensch ist, da eine Maschine diese unmöglich entziffern kann, oder? Falsch. XRumer ist in der Lage eine ganze Reihe solcher Captchas zu identifizieren und auszulesen — sogar drei Versionen, an denen ich z.B. regelmäßig scheitere. Die Liste findet sich unten im Blogeintrag.
Um den Eintrag abzurunden gibt es auch ein Video, welches die Software in Aktion zeigt. Sehr beeindruckend, aber auch sehr sehr beängstigend, mit welch geringem Einsatz so ein Müll verbreitet werden kann.
Stirb Spammer, stirb
Geschrieben um 12:44
[/computer/internet] [permanent link] [Startseite]
Was bedeutet eigentlich “Hot pluggable”?
2007-03-23Das ist eigentlich ganz einfach: Bei uns Computermenschen bezeichnet man Hardware, die man im laufenden Betrieb ein- oder ausstöpseln kann, als “hot pluggable”. Das geht mittlerweile soweit, dass man bei bestimmten Rechnertypen (und bei Unterstützung durch das Betriebssystem) CPUs und Speicher austauschen kann, während der Rechner weiterläuft.

Das wohl bekannteste dieser “hot-plug”-Systeme dürfte USB sein. Der Rechner läuft, man stöpselt seine Kamera an, ein Programm startet und man kopiert die Bilder von der Kamera auf den Rechner. Oder man steckt eine USB-Festplatte ein, weil man den dort gespeicherten Film sehen will. Oder man stöpselt den Scanner ein, um Bilder einzuscannen. Oder. Oder. Oder. Alles im laufenden Betrieb.
Man kann natürlich auch versuchen, nur ein USB-Kabel einzustöpseln, damit man dann — wann immer man will — eines dieser Geräte anschließen kann. Muss ja nicht sofort sein. Eventuell morgen. Oder gar erst übermorgen. Aber das Kabel soll schon mal bereitliegen.
Warum ist jetzt gerade eigentlich der Bildschirmschoner angegangen? Moment. Warum ist die NumLock-Taste nicht mehr an? Ist der Rechner noch an? Nein? Warum nicht?
Und was riecht hier eigentlich so komisch? Der Rechner lässt sich auf jeden Fall nicht mehr einschalten. Kollege sagt: “Da hast du dir wahrscheinlich das Netzteil gehimmelt. Ich besorg dir mal eine neues”. Netzteil isses aber auch nicht, der Fehler will also eingegrenzt werden. Erst einmal alle Peripheriegeräte ausstöpseln. Festplatten, CD-ROM, Floppy. Tut immer noch nicht.
Hmmmm. Noch mal das alte Netzteil anschließen. Moment. Noch nicht einschalten, was ist denn das auf der North Bridge? Ein Loch? “Schalt mal kurz ein” — die Lüfter starten und eine kleine Rauchfahne weht aus dem Loch hervor. Heiß geplugget.
Und mal wieder ein Beweis für das Sprichwort: “Wenn der magische Rauch erst einmal aus einem elektrischen Gerät entwichen ist, dann funktioniert es nicht mehr. Elektrische Geräte benötigen magischen Rauch.”
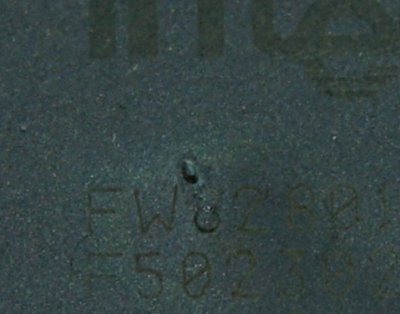
Geschrieben um 18:20
[/computer/hardware] [permanent link] [Startseite]
Gallery und Creative Commons-Lizenzen
2007-03-13Gestern habe ich mir ein wenig den Kopf zerbrochen, wie ich die Bilder in meiner Gallery mit einer vernünftigen Lizenz versehen kann. Meinetwegen kann die jeder nutzen und verändern, solange er dazuschreibt dass das meine Bilder sind, er sie auch unter einer solchen Lizenz weitergibt und er die Bilder nicht kommerziell nutzt. Creative Commons bieten solche Lizenzen, in meinem Fall die “Attribution-Noncommercial-Share Alike”-Lizenz. Doch wie bekomme ich die nun in die Gallery?
Meine erste Idee war es, den Link zur Lizenz auf allen Seiten der Gallery anzeigen zu lassen. Dazu hätte man ein wenig im Code fummeln müssen, irgendwie hätte das bestimmt funktioniert. Aber wenn jemand nur einen Link auf eines der Bilder bekommt, dann bekommt er die Lizenz nicht zu Gesicht.
Es gibt da aber einen Standard des International Press Telecommunications Council, der es erlaubt, Metadaten direkt in ein Bild einzubetten, unter anderem Copyrightinformationen. Ein weiterer dieser Standards ist XMP, der RDF in Binärdaten einbetten kann. Um den Kreis zu schließen, bietet Creative Commons ein XMP-Template an, welches die Lizenz enthält.
Mit Exiftool kann man dieses Template in die Bilder einbetten. Und genauso kann man mit exiftool ein IPTC:CopyrightNotice in die Bilder schreiben. Und genau dieses IPTC:CopyrightNotice wird von Gallery ausgewertet und unterhalb des Bildes auf der Webseite angezeigt. Also alle Wünsche erfüllt: Die Lizenz ist im Bild enthalten — einmal nach XMP, einmal nach IPTC-Standard — und wird von Gallery unterhalb des Bildes angezeigt.
Um mir das Gefummel auf der Kommandozeile zu vereinfachen, habe ich mir ein kleines Skript geschrieben, welches diese Einträge in den Bildern für mich vornimmt. Eventuell ist das ja auch für jemanden anders nützlich:
# This little script adds a creative commons license to your .jpeg pictures
# from your digital camera.
#
# You need exiftool: http://www.sno.phy.queensu.ca/~phil/exiftool/. This will
# probably already be packaged by your distribution. Make sure that exiftool is
# in your $PATH
#
# 1. Go to http://www.creativecommons.org/ and select "License your Work"
# 2. Click through the wizard to get the license you want to have
# 3. Download the XMP template (right hand side, look for PDF)
# 4. Run this script on a folder with .jpg files in it
# 5. Check your pictures. If they are okay, you can delete the "*_original" files
# 6. Done
usage() {
echo -e "Usage: add-cc.sh jpegdir, where jpegdir is a directory with pictures in it"
exit 127
}
die_no_dir() {
echo -e "$JPEGDIR is not a directory"
exit 127
}
[ "x$1" != "x" ] || usage
# Point this to your licensefile
LICENSEFILE="/home/ralph/Desktop/bilder/cc-license.xmp"
JPEGDIR=$1
[ -d "${JPEGDIR}" ] || die_no_dir
for picture in "${JPEGDIR}"/*.{jpg,jpeg,JPG,JPEG}; do
exiftool -TagsFromFile "${LICENSEFILE}" "${picture}"
exiftool -TagsFromFile "${picture}" '-xmp:rights>iptc:copyrightnotice' "${picture}"
done
Man benötigt das XMP-Template von Creative Commons mit der
passenden Lizenz und ein Verzeichnis mit .jpg- oder .jpeg-Dateien. Der
Speicherort des XMP-Templates muss dem Skript dann noch via
LICENSEFILE bekanntgemacht werden. Danach wird das Skript mit
add-cc.sh directory aufgerufen, wobei directory
das Verzeichnis mit den Bildern ist. Das bedingt natürlich, dass man seine
Bilder in Einzelverzeichnissen speichert und alle Bilder unter diese Lizenz
stellen möchte. Wer das anders macht, kann dem Skript aber leicht entnehmen,
wie die beiden Aufrufe von exiftool aussehen und das an seine
Bedürfnisse anpassen.
Wie das ganze im Bild aussieht, kann man sich mit exiftool -v
bild.jpg anschauen, wie das in der Gallery aussieht, kann man in den
Photo-Eigenschaften
unterhalb des Bildes sehen.
Jetzt muss sich nur noch jeder dran halten.
Den Inhalt dieses Blogs habe ich dann ebenfalls unter diese Lizenz gestellt. Siehe Seite ganz unten …
Geschrieben um 21:22
[/computer/freesoftware] [permanent link] [Startseite]
Oracle does a CentOS
2006-11-05Mittlerweile ist die Ankündigung eine Woche alt, dass Oracle sich entschieden hat eine eigene Linuxdistribution herauszubringen. Mittlerweile hatte ich eine Woche Zeit, mich am Kopf zu kratzen und mich zu fragen, was Larry Ellison sich dabei gedacht hat. Und mittlerweile weiß ich auch, dass ich mir die Frage nicht zufriedenstellend beantworten kann.
Da wäre zuerst einmal die Supportfrage: Wer an Oracle denkt, denkt zuerst einmal an Datenbanken, nicht an Betriebssysteme. Wer Oracle kennt, kennt zuerst einmal die Datenbanken. Was er normalerweise nicht kennt, ist Support. Der ist nämlich nicht so dolle. Warum man dann versucht, sich gerade im Linuxbereich in der Supportschiene einen Namen machen zu wollen ist mehr als rätselhaft.
Dann wäre da die Distribution selber. Gerüchte über eine eigene Distribution gibt es schon länger, auch die Gerüchte über den Aufkauf einer schon bekannten Distribution gab es zu Genüge. Mit einem “Rebuild” von Redhat Enterprise Linux hat aber wohl niemand so wirklich gerechnet. Und so richtig ist es ja auch keiner. Erstens hat man sich an einigen Stellen bei CentOS bedient, natürlich nicht ohne Hinweise auf CentOS aus den Paketen zu entfernen. Zweitens hat man angefangen Pakete umzubenennen, so z.B. das Kernelpaket. Dadurch ergibt sich folgendes Problem: Kerneltreiber von anderen Herstellern, die sich bei der Installation von RHEL oder CentOS ohne weiteres von Treiberdisketten nachladen lassen, sind nicht nutzbar.
Dann wäre da die Distribution selber: Erste Tests zeigen, dass das ein Schnellschuss war. Leere Applikationsmenüs, von CentOS übernommenene Texte beim Start des Browsers (man vergleiche das mit dem ersten Absatz im CentOS Overview) und noch einige andere “Fehlerchen” mehr sind denn doch recht auffällig.
{kind=link}
Ebenfalls von CentOS übernommen wurde Yum, und zwar inklusive eines Paketes mit dem Namen “oracle-yumconf”, welches erstens unter CentOS seit 4.4 nicht mehr vorhanden ist und zweitens bei Oracle auf Updateserver verweist, die ebenfalls nicht vorhanden sind. Was Oracle jetzt genau nutzt, um Kunden updates zu ermöglichen, ist mir nicht persönlich bekannt. Es scheint allerdings Current zu sein. Was ein weiteres Problem aufwirft: Current benötigt eine ziemlich neue Version von yum, die laut dem Maintainer von yum eine Version von RPM vorraussetzt, die in RHEL 4 nicht vorhanden ist.
Das sieht also doch eher nach einem Fork aus, als nach einem reinen Nachbau. Damit hat sich dann auch das Thema “Binärkompatibilität” aus dem von CentOS entlehnten Absatz.
Natürlich hat RedHat reagiert: Antworten auf das “Angebot” von Oracle. Vom CentOS-Team gibt es ebenfalls eine Stellungnahme zu Oracles Linux, entstanden aus einer Q&A-Session mit Linux Planet.
Ich bin eigentlich nur gespannt, wann Larry Ellison das Interesse wieder verliert. Ich tippe auf Anfang 2007, also dem Zeitpunkt, wenn RHEL5 auf dem Markt ist. Weil: Überzeugt bin ich von dem, was Oracle bisher geliefert hat, nicht. Wirklich.
Geschrieben um 13:08
[/computer/linux] [permanent link] [Startseite]
Sowas von gar nicht Web-2.0
2006-08-25Tja. Leider verloren. Blogs sind also kein Web-2.0. Aber so richtig überhaupt nicht: “The score for http://lestighaniker.de/ is 4 out of 52” — damit kann man heute keinen Venture-Kapitalisten mehr aus dem wohlverdienten Bürofschlaf reißen. Aber andere sind ja auch nicht besser:

- The score for http://www.amazon.de is 3 out of 52
- The score for http://www.spiegel.de is 7 out of 52
- The score for http://www.oreilly.com is 11 out of 51 - immerhin, hat dort doch der ganze Hype angefangen
- The score for http://www.google.com is 2 out of 52
- usw.
Wer also ist dann Web-2.0, wenn schon das W3C nur 7 Punkte bekommt? Wenn Flickr nur 4 Punkte bekommt? Und auch Google Maps mit 6 Punkten nur wenig besser ist? Muss es Beta sein? Fehlen tag clouds? Sind Ruby on Rails oder Ajax oder Python notwendig? Muss man verstanden haben, was das Semantic Web ist? Runde Ecken? Nitro? MonoRail? Podcasting?
Egal, jetzt gibt es Abhilfe. Der Web-2.0 Validator hilft einem dabei, seine Seite für Web-2.0 zu rüsten. Soll ja keiner sagen können, er habe nicht gewusst, worauf es ankommt.
Update: Immerhin schon 14 von 52 möglichen Punkten. Da muss sich doch noch mehr rausholen lassen …
Geschrieben um 17:36

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.0 Germany License.